 code shamelessly borrowed from : http://adolfoalvarez.cl/the-hitchhikers-guide-to-the-hadleyverse/
code shamelessly borrowed from : http://adolfoalvarez.cl/the-hitchhikers-guide-to-the-hadleyverse/
February 2, 2016
Hadleyverse
Hadleyverse
- Ingest (rvest, readr, readxl)
- Manipulate (dplyr)
- Visualize (ggplot2, ggvis)
- Create packages (devtools, testthat)
- Simplify programming (purrr, lazyeval)
- and data packages (ggplot2movies, nycflights13)
dplyr
dplyr provides a set of tools to assemble, transform, and summarize your data.
Single table verbs
dplyr implements the following verbs useful for data manipulation:
select(): focus on a subset of variablesfilter(): focus on a subset of rowsmutate(): add new columnssummarise(): reduce each group to a smaller number of summary statisticsarrange(): re-order the rows
More information about single table verbs
Michael Levy's Intro to dplyr presentation to D-RUG Oct. 2014 http://michaellevy.name/blog/dplyr-data-manipulation-in-r-made-easy/
Multiple table verbs (Joins)
In addition to single table verbs, there are also a set of verbs that operate on two tables at a time: joins and set operations.
- Joins
inner_join(x, y): matching x + yleft_join(x, y): all x + matching ysemi_join(x, y): all x with match in yanti_join(x, y): all x without match in y
- Sets
intersect(x, y): all rows in both x and yunion(x, y): rows in either x or ysetdiff(x, y): rows in x, but not y
Why Joins?
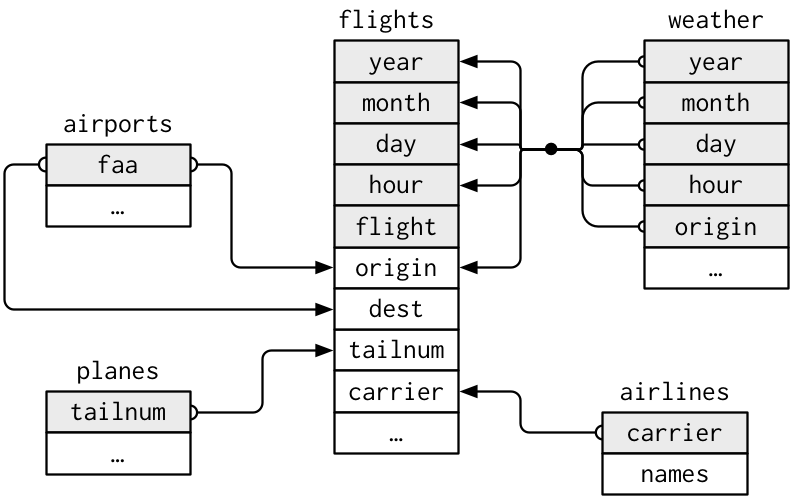
Example Data Joins
require(dplyr) set.seed(12345) #that's amazing, I've got the same combination on my luggage! x <- data.frame(key= LETTERS[c(1:3, 5)], value1 = sample(1:10, 4), stringsAsFactors = FALSE) y <- data.frame(key= LETTERS[c(1:4)], value2 = sample(1:10, 4), stringsAsFactors = FALSE) x
## key value1 ## 1 A 8 ## 2 B 10 ## 3 C 7 ## 4 E 9
y
## key value2 ## 1 A 5 ## 2 B 2 ## 3 C 3 ## 4 D 4
inner_join

inner_join(x, y, by = "key")
## key value1 value2 ## 1 A 8 5 ## 2 B 10 2 ## 3 C 7 3
left_join

left_join(x, y, by = "key")
## key value1 value2 ## 1 A 8 5 ## 2 B 10 2 ## 3 C 7 3 ## 4 E 9 NA
right_join

right_join(x, y, by = "key")
## key value1 value2 ## 1 A 8 5 ## 2 B 10 2 ## 3 C 7 3 ## 4 D NA 4
full_join

full_join(x, y, by = "key")
## key value1 value2 ## 1 A 8 5 ## 2 B 10 2 ## 3 C 7 3 ## 4 E 9 NA ## 5 D NA 4
Duplicate keys


Filtering Joins
Semi and Anti joins don't actually join two datasets together. They filter one dataset based upon what's in another. This is useful when:
- you want to filter your dataset based upon another (semi)
- or want to understand what isn't in both datasets (anti)
semi_join

semi_join(x, y, by = "key")
## key value1 ## 1 A 8 ## 2 B 10 ## 3 C 7
anti_join

anti_join(x, y, by = "key")
## key value1 ## 1 E 9
Want everything that doesn't match?
Combine join statements.
full_join(anti_join(x,y, by = "key"), anti_join(y,x, by = "key"), by= "key")
## key value1 value2 ## 1 E 9 NA ## 2 D NA 4
Different keys?
Real data is messy. If key1 is "date" and key2 is "Date" things break. So, specify:
set.seed(12345) #that's amazing, I've got the same combination on my luggage! x <- data.frame(keyX= LETTERS[c(1:3, 5)], value1 = sample(1:10, 4), stringsAsFactors = FALSE) y <- data.frame(keyY= LETTERS[c(1:4)], value2 = sample(1:10, 4), stringsAsFactors = FALSE) full_join(x, y)
## Error: No common variables. Please specify `by` param.
full_join(x, y, by=c("keyX" = "keyY"))
## keyX value1 value2 ## 1 A 8 5 ## 2 B 10 2 ## 3 C 7 3 ## 4 E 9 NA ## 5 D NA 4
Set operations
You have two datasets that should be the same, but you're not sure if they are. How do you easily test that they are the same?
- Sets
intersect(x, y): all rows in both x and yunion(x, y): rows in either x or ysetdiff(x, y): rows in x, but not y
Set Operations

Example Data Set Ops
df1 <- data_frame(x = LETTERS[1:2], y = c(1L, 1L)) df2 <- data_frame(x = LETTERS[1:2], y = 1:2) df1
## Source: local data frame [2 x 2] ## ## x y ## (chr) (int) ## 1 A 1 ## 2 B 1
df2
## Source: local data frame [2 x 2] ## ## x y ## (chr) (int) ## 1 A 1 ## 2 B 2
intersect
Which rows are common in both datasets?
dplyr::intersect(df1, df2)
## Source: local data frame [1 x 2] ## ## x y ## (chr) (int) ## 1 A 1
union
Want all unique rows between both datasets?
dplyr::union(df1, df2)
## Source: local data frame [3 x 2] ## ## x y ## (chr) (int) ## 1 B 2 ## 2 B 1 ## 3 A 1
setdiff
What's unique to df1?
dplyr::setdiff(df1, df2)
## Source: local data frame [1 x 2] ## ## x y ## (chr) (int) ## 1 B 1
What's unique to df2?
dplyr::setdiff(df2, df1)
## Source: local data frame [1 x 2] ## ## x y ## (chr) (int) ## 1 B 2
Questions
More information: - http://r4ds.had.co.nz/relational-data.html
All diagrams courtesy of Hadley Wickham