3 Scraping structured data iteravely
3.1 Scrape one example
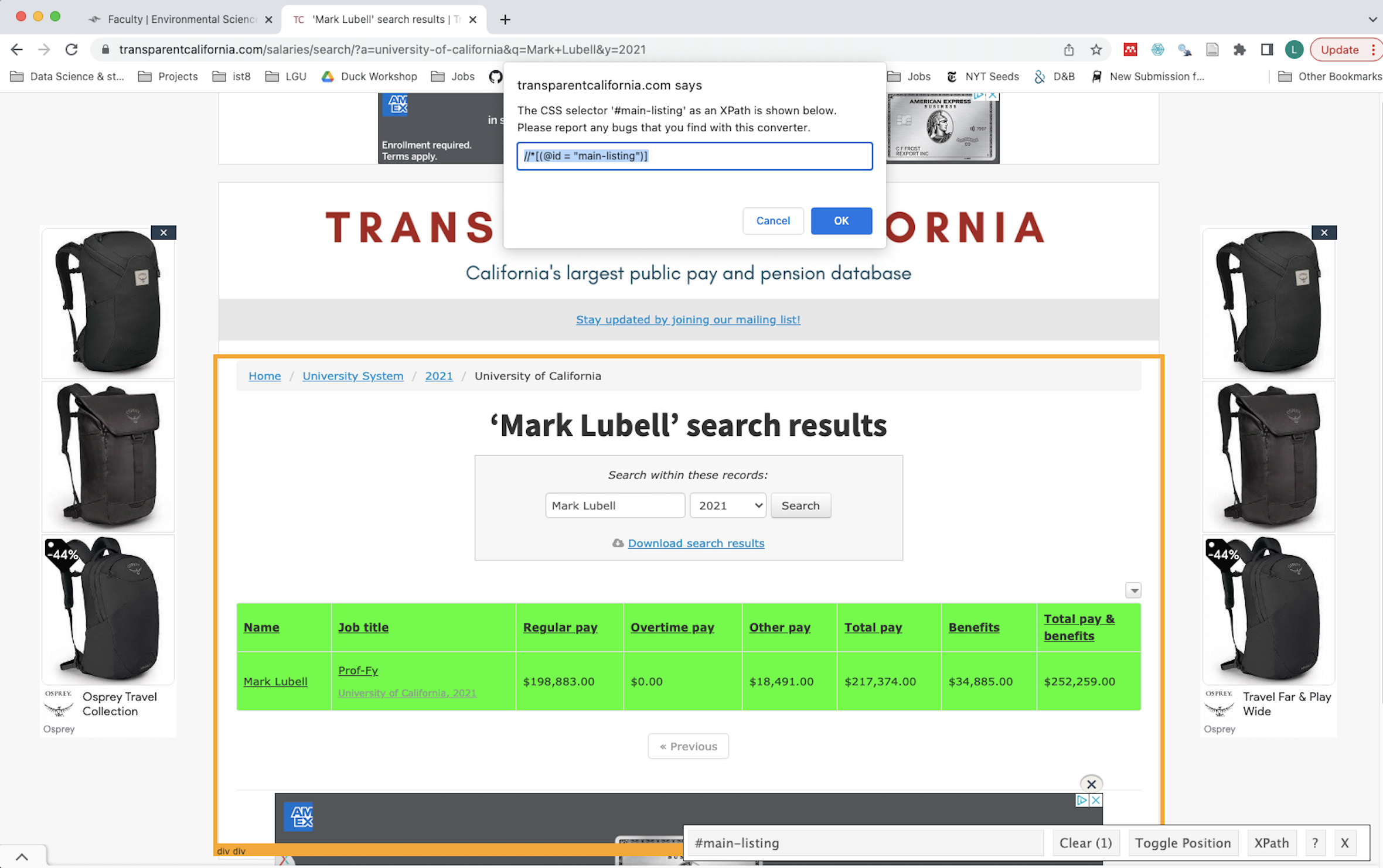
So let’s figure figure out the xpath to scrape one person’s salary data, then we can iterate across multiple names.
Let’s follow the same steps we used to scrape a faculty webpage. I know that there is a table in there, so I can use InspectorGadget to help me identify its path.
picture of InspectorGadget tool
Inspector gadget gave me //*[(@id = "main-listing")], which when run in xml_find_all() we see the output is a list with table elements.
url <- "https://transparentcalifornia.com/salaries/search/?a=university-of-california&q=Mark+Lubell&y=2021"
page <- read_html(url) %>%
xml_find_all('//*[(@id = "main-listing")]')
page## {xml_nodeset (1)}
## [1] <table class="table table-hover table-bordered" id="main-listing" data-ta ...Since we have a table, now instead of just reading the text we can use rvest’s html_table() function to read the table and wrap it in data.frame() to make it readable.
table <- page %>%
html_table() %>%
data.frame()
table## Name Job.title Regular.pay Overtime.pay
## 1 Mark Lubell Prof-FyUniversity of California, 2021 $198,883.00 $0.00
## Other.pay Total.pay Benefits Total.pay...benefits
## 1 $18,491.00 $217,374.00 $34,885.00 $252,259.003.2 Iterating scrape across URLs
Now we the know how to scrape one page, we want to generalize this scraping so that we can input multiple URLs. We’ve wrapped the earlier code into a function with only one argument – the URL.
scrape_fx <- function(URL){
url <- URL
df <- read_html(url) %>%
xml_find_all('//*[(@id = "main-listing")]') %>%
html_table() %>%
data.frame()
return(df)
}Now we can apply that function across all of the URLs so that we can compile salary data for all faculty.
salary.list <- lapply(faculty$url, scrape_fx)
salary.df <- do.call("rbind", salary.list)Now we can take a look:
DT::datatable(salary.df, rownames = F)